![]() 𝐅𝐢𝐧𝐝𝐢𝐧𝐠 𝐂𝐥𝐨𝐬𝐞𝐬𝐭 𝐆𝐞𝐨𝐠𝐫𝐚𝐩𝐡𝐢𝐜𝐚𝐥 𝐏𝐨𝐢𝐧𝐭𝐬: 𝐀 𝐂𝐨𝐦𝐩𝐚𝐫𝐚𝐭𝐢𝐯𝐞 𝐀𝐩𝐩𝐫𝐨𝐚𝐜𝐡
𝐅𝐢𝐧𝐝𝐢𝐧𝐠 𝐂𝐥𝐨𝐬𝐞𝐬𝐭 𝐆𝐞𝐨𝐠𝐫𝐚𝐩𝐡𝐢𝐜𝐚𝐥 𝐏𝐨𝐢𝐧𝐭𝐬: 𝐀 𝐂𝐨𝐦𝐩𝐚𝐫𝐚𝐭𝐢𝐯𝐞 𝐀𝐩𝐩𝐫𝐨𝐚𝐜𝐡
In the world of data science and geospatial analysis, identifying the closest points between datasets is a common yet crucial task. Recently, I explored two different methodologies to achieve this objective using Python.
![]() 𝑪𝒂𝒓𝒕𝒆𝒔𝒊𝒂𝒏 𝑷𝒓𝒐𝒅𝒖𝒄𝒕 𝒂𝒏𝒅 𝑯𝒂𝒗𝒆𝒓𝒔𝒊𝒏𝒆 𝑭𝒐𝒓𝒎𝒖𝒍𝒂
𝑪𝒂𝒓𝒕𝒆𝒔𝒊𝒂𝒏 𝑷𝒓𝒐𝒅𝒖𝒄𝒕 𝒂𝒏𝒅 𝑯𝒂𝒗𝒆𝒓𝒔𝒊𝒏𝒆 𝑭𝒐𝒓𝒎𝒖𝒍𝒂
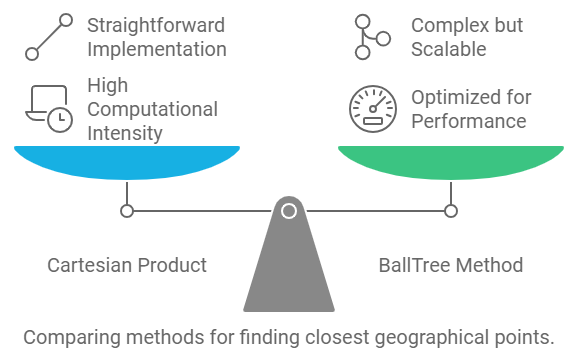
The first approach involves calculating the Cartesian product of two datasets and applying the Haversine formula to determine distances. While this method is straightforward, it can be computationally intensive for larger datasets.
![]() Check out the code here: Python_For_RF_Optimization_And_Planning_Engineer/Distance/Calculate_Min_Distance_Using_haversine.md at main · Umersaeed81/Python_For_RF_Optimization_And_Planning_Engineer · GitHub
Check out the code here: Python_For_RF_Optimization_And_Planning_Engineer/Distance/Calculate_Min_Distance_Using_haversine.md at main · Umersaeed81/Python_For_RF_Optimization_And_Planning_Engineer · GitHub
![]() 𝑬𝒇𝒇𝒊𝒄𝒊𝒆𝒏𝒕 𝑵𝒆𝒂𝒓𝒆𝒔𝒕 𝑵𝒆𝒊𝒈𝒉𝒃𝒐𝒓 𝑺𝒆𝒂𝒓𝒄𝒉 𝒘𝒊𝒕𝒉 𝑩𝒂𝒍𝒍𝑻𝒓𝒆𝒆
𝑬𝒇𝒇𝒊𝒄𝒊𝒆𝒏𝒕 𝑵𝒆𝒂𝒓𝒆𝒔𝒕 𝑵𝒆𝒊𝒈𝒉𝒃𝒐𝒓 𝑺𝒆𝒂𝒓𝒄𝒉 𝒘𝒊𝒕𝒉 𝑩𝒂𝒍𝒍𝑻𝒓𝒆𝒆
The second approach leverages the BallTree data structure for a more efficient nearest neighbor search. This method is optimized for performance, especially when working with larger datasets, making it a more scalable solution.
![]() Check out the code here: Python_For_RF_Optimization_And_Planning_Engineer/Distance/Calculate_Min_Distance_Using_sklearn.md at main · Umersaeed81/Python_For_RF_Optimization_And_Planning_Engineer · GitHub
Check out the code here: Python_For_RF_Optimization_And_Planning_Engineer/Distance/Calculate_Min_Distance_Using_sklearn.md at main · Umersaeed81/Python_For_RF_Optimization_And_Planning_Engineer · GitHub
Both methods ultimately aim to identify the closest geographical points, but they differ significantly in their performance and complexity. I encourage fellow data enthusiasts to take a look and consider which approach best suits their needs!
Feel free to share your thoughts and experiences in the comments below!